...
| Code Block | ||||
|---|---|---|---|---|
| ||||
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: connect
namespace: kafka
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
namespace: kafka
annotations:
# use-connector-resources configures this KafkaConnect
# to use KafkaConnector resources to avoid
# needing to call the Connect REST API directly
strimzi.io/use-connector-resources: "true"
spec:
image: ktimoney/strimzi-influxdb-connect
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
- secretName: my-cluster-clients-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: connect
certificate: user.crt
key: user.key
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1 |
...
The KafkaConnector is configured to use the "org.apache.camel.kafkaconnector.influxdb.CamelInfluxdbSinkConnector" class.
The value converter are is set to "org.apache.kafka.connect.json.JsonConverter".
...
| Code Block | ||||
|---|---|---|---|---|
| ||||
{'pretty': 'true', 'db': 'ts_host_metrics', 'q': 'SELECT "region", "host", "free", "used" FROM "disk_space" WHERE "host"=\'localhost\''}
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "disk_space",
"columns": [
"time",
"region",
"host",
"free",
"used"
],
"values": [
[
"2023-01-23T13:03:32.1246436Z",
"IE-region",
"localhost",
"81%",
"19%"
]
]
}
]
}
]
} |
Links
Minio Sink Connector (Apache Camel)
Prepare the connector image
Download the minio sink connector: wget https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-file-kafka-connector/3.20.0/camel-file-kafka-connector-3.20.0-package.tar.gz
We need to create some custom classes:
CamelMinioConverters.java - this will allow us to deserialize to json and convert the hashmap to an inputstream
| Code Block | ||||
|---|---|---|---|---|
| ||||
package com.custom.convert.minio;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.ByteArrayInputStream;
import java.io.InputStream;
import java.util.Map;
import org.apache.camel.Converter;
@Converter(generateLoader = true)
public final class CamelMinioConverters {
private CamelMinioConverters() {
}
@SuppressWarnings("deprecation")
@Converter
public static InputStream fromMapToInputStream(Map<String, Object> map) {
String json = "{}";
try {
json = new ObjectMapper().writeValueAsString(map);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return new ByteArrayInputStream(json.getBytes());
}
} |
StringAggregator.java - this will allow us to aggregate the messages and set the file name
| Code Block | ||||
|---|---|---|---|---|
| ||||
package com.custom.aggregate.minio;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import org.apache.camel.AggregationStrategy;
import org.apache.camel.Exchange;
import org.apache.camel.Message;
public class CustomStringAggregator implements AggregationStrategy {
//@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange) {
Message newIn = newExchange.getIn();
Map<String, String> keyMap = (HashMap) newIn.getHeaders().get("camel.kafka.connector.record.key");
String key = keyMap.get("id");
SimpleDateFormat sdf = new SimpleDateFormat("ddMMyy-hhmmss-SSS");
String fileName = "ExchangeKafka-" + key + "-" + sdf.format( new Date() ) + ".json";
newIn.setHeader("file", fileName);
// lets append the old body to the new body
if (oldExchange == null) {
return newExchange;
}
String body = oldExchange.getIn().getBody(String.class);
if (body != null) {
String newBody = newIn.getBody(String.class);
if (newBody != null) {
body += System.lineSeparator() + newBody;
}
newIn.setBody(body);
}
return newExchange;
}
} |
We can then create a custom jar for our code and copy it into the docker container.
Note: You can also set the filename in the Kafka header using either CamelHeader.file or CamelHeader.ce-file
Create a docker file for this connector
| Code Block | ||||
|---|---|---|---|---|
| ||||
FROM quay.io/strimzi/kafka:0.32.0-kafka-3.3.1
USER root:root
RUN mkdir -p /opt/kafka/plugins/camel
COPY ./camel-minio-sink-kafka-connector-3.20.0-package.tar.gz /opt/kafka/plugins/camel/
RUN tar -xvzf /opt/kafka/plugins/camel/camel-minio-sink-kafka-connector-3.20.0-package.tar.gz --directory /opt/kafka/plugins/camel
COPY ./custom-converter-1.0.0.jar /opt/kafka/plugins/camel/camel-minio-sink-kafka-connector/
RUN rm /opt/kafka/plugins/camel/camel-minio-sink-kafka-connector-3.20.0-package.tar.gzRUN rm -rf /opt/kafka/plugins/camel/docs
USER 1001 |
Build the image and copy it to your docker repository
docker build -f Dockerfile . t ktimoney/strimzi_minio_connector
Prepare the message producer
In this example we are going to deserialize the value to a string. (Same producer as the influxdb example)
They will take the following format:
| Code Block | ||||
|---|---|---|---|---|
| ||||
{
"camelInfluxDB.MeasurementName":"disk_space"
"time":"2023-01-23T13:03:31Z"
"host":"localhost"
"region":"IE-region"
"used":"19%"
"free":"81%"
} |
With the type converter n place we can also deserialize as a json object.
They key will be a json that loos like this: {"id":"119"}
Create the KafkaConnect object
| Code Block | ||||
|---|---|---|---|---|
| ||||
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: connect
namespace: kafka
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
namespace: kafka
annotations:
# use-connector-resources configures this KafkaConnect
# to use KafkaConnector resources to avoid
# needing to call the Connect REST API directly
strimzi.io/use-connector-resources: "true"
spec:
image: ktimoney/strimzi-minio-connect
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
- secretName: my-cluster-clients-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: connect
certificate: user.crt
key: user.key
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# -1 means it will use the default replication factor configured in the broker
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1 |
We are connecting to the 9093 tls port so we include required certificates in our configuration.
The image tag references the image we built earlier : ktimoney/strimzi-minio-connect
Create the Sink connector
| Code Block | ||||
|---|---|---|---|---|
| ||||
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-sink-connector
namespace: kafka
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: org.apache.camel.kafkaconnector.miniosink.CamelMiniosinkSinkConnector
tasksMax: 1
config:
topics: my-topic
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable: false
value.converter.schemas.enable: false
camel.beans.aggregate: "#class:com.custom.aggregate.minio.CustomStringAggregator"
camel.aggregation.size: 1
camel.aggregation.timeout: 20000
camel.aggregation.disable: false
camel.kamelet.minio-sink.bucketName: camel
camel.kamelet.minio-sink.accessKey: ybK7RleFUkdDeYBf
camel.kamelet.minio-sink.secretKey: X0Y4zK84bwdefRTljrnPzOb1l0A6OQj2
camel.kamelet.minio-sink.endpoint: http://minio.default:9000
camel.kamelet.minio-sink.autoCreateBucket: true |
The KafkaConnector is configured to use the "org.apache.camel.kafkaconnector.miniosink.CamelMiniosinkSinkConnector class.
The value converter is set to "org.apache.kafka.connect.storage.StringConverter".
The minio connection details are specified in camel.kamelet.minio-sink parameters.
The aggregation size is set to 1 so it won't aggregate any of the files
This timeout is also specified so it will only aggregate records arriving within this time out value (20 seconds).
These values can be adjusted depending on your requirements.
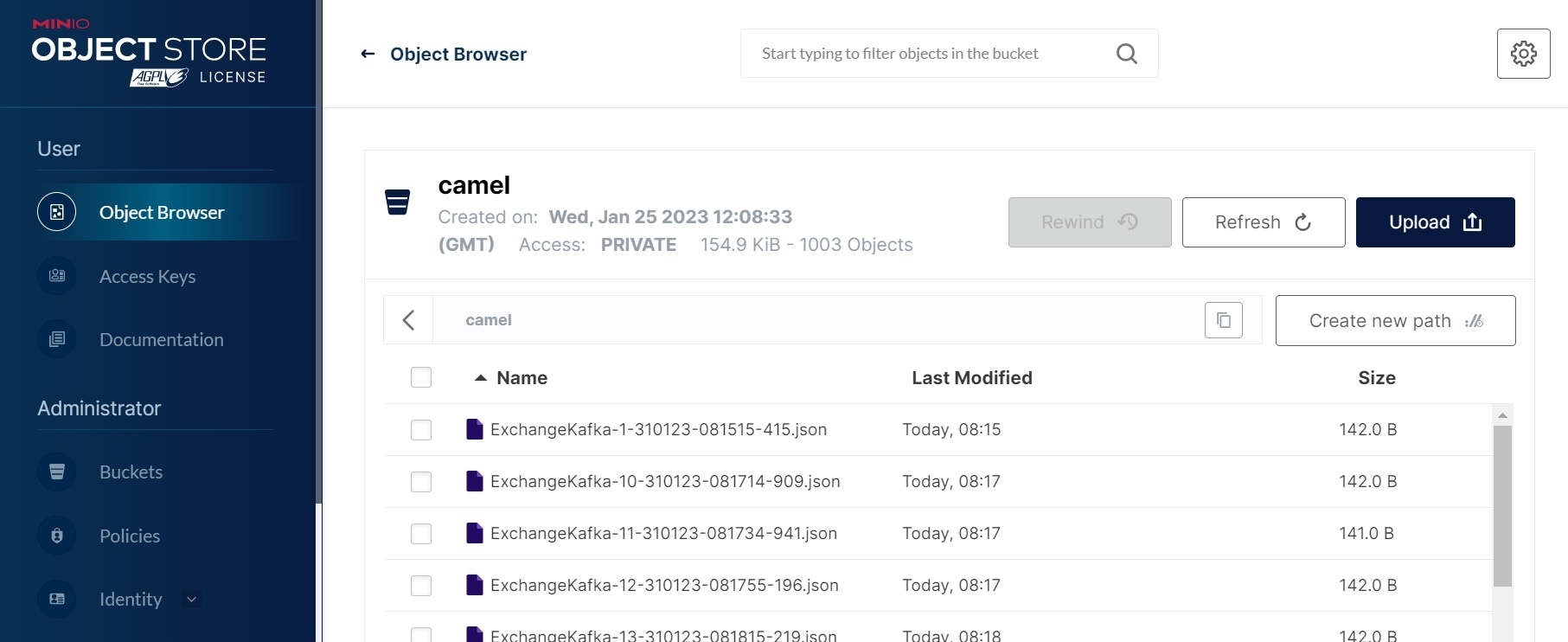
The main purpose of the aggregator in this example is for setting the file name, this is done by setting a header with a key of "file".
The yaml for the minio pod is available here: minio.yaml
When the connector is running it copies the kafka records into minio as files:
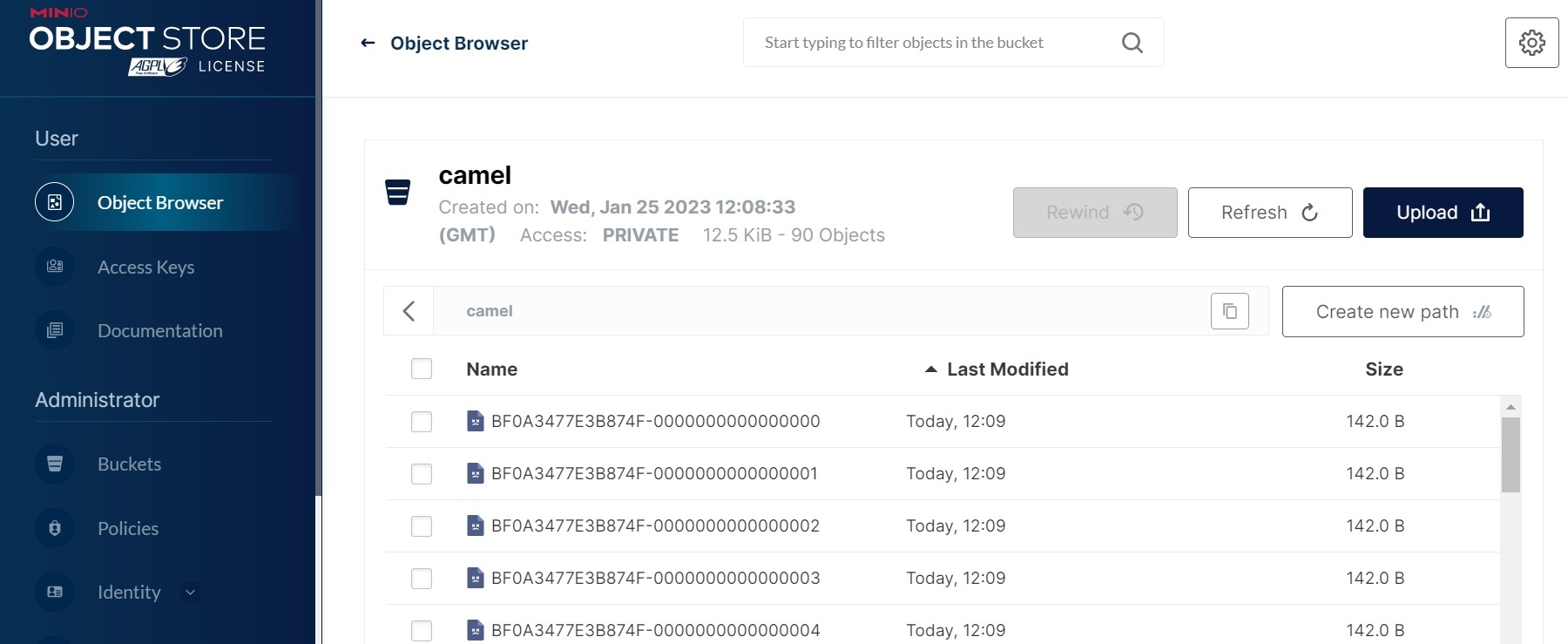
Here's a screen shot where we use the aggregator to set the file name:
File Sink Connector (Apache Camel)
Prepare the connector image
Download the file connector: wget https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-file-kafka-connector/3.20.0/camel-file-kafka-connector-3.20.0-package.tar.gz
Create a docker file for this connector
| Code Block | ||||
|---|---|---|---|---|
| ||||
FROM quay.io/strimzi/kafka:0.32.0-kafka-3.3.1
USER root:root
RUN mkdir -p /opt/kafka/plugins/camel
COPY ./camel-file-kafka-connector-3.20.0-package.tar.gz /opt/kafka/plugins/camel/
RUN tar -xvzf /opt/kafka/plugins/camel/camel-file-kafka-connector-3.20.0-package.tar.gz --directory /opt/kafka/plugins/camel
RUN rm /opt/kafka/plugins/camel/camel-file-kafka-connector-3.20.0-package.tar.gz
RUN rm -rf /opt/kafka/plugins/camel/docs
USER 1001 |
Build the image and copy it to your docker repository
docker build -f Dockerfile . t ktimoney/strimzi_file_connector
Prepare the message producer
In this example we are going to deserialize the value to a string.
The value will take the following format:
| Code Block | ||||
|---|---|---|---|---|
| ||||
{
"camelInfluxDB.MeasurementName":"disk_space"
"time":"2023-01-23T13:03:31Z"
"host":"localhost"
"region":"IE-region"
"used":"19%"
"free":"81%"
} |
Due to some limitation with Strimzi KafkaConnect we will need to use a mutating webhook to attach a persistent volume to our connector pod.
The go code for this is available here: kafka-webhook.go
We need to create a docker image for this program
| Code Block | ||||
|---|---|---|---|---|
| ||||
FROM golang:latest
RUN mkdir /app
COPY ./kafka-webhook /app
RUN chmod +x /app/kafka-webhook
WORKDIR /app
ENTRYPOINT ["/app/kafka-webhook"] |
docker build -f Dockerfile . -t ktimoney/kafka-webhook
Mutating webhooks require https so we also need to create some certificates.
Make sure cfssl is installed on you system, then run the following commands.
cfssl gencert -initca ./ca-csr.json | cfssljson -bare ca
cfssl gencert \
-ca=ca.pem \
-ca-key=ca-key.pem \
-config=ca-config.json \
-hostname="kafka-webhook,kafka-webhook.kafka.svc.cluster.local,kafka-webhook.kafka.svc,localhost,127.0.0.1" \
-profile=default \
ca-csr.json | cfssljson -bare webhook-cert
Run the following commands to create the values you need to use in the yaml file:
TLS_CRT=$(cat webhook-cert.pem | base64 | tr -d '\n')
TLS_KEY=$(cat webhook-cert-key.pem | base64 | tr -d '\n')
CA_BUNDLE="$(openssl base64 -A <"ca.pem")"
Replace the values in : kafka-webhook.yaml
Note: You can also configure the hostPath and the containerPath as part of the deployment:
| Code Block | ||||
|---|---|---|---|---|
| ||||
containers:
- name: kafka-webhook
image: ktimoney/kafka-webhook
imagePullPolicy: IfNotPresent
command: ["/app/kafka-webhook"]
args: [
"-port", "8443",
"-tlsCertFile", "/certs/tls.crt",
"-tlsKeyFile", "/certs/tls.key",
"-hostPath", "/var/strimzi/files",
"-containerPath", "/opt/kafka/data"
] |
Run: kubectl create -f kafka webhook.yaml to start the pod.
Note: You can delete the webhook once the connector pod starts.
Create the KafkaConnect object
| Code Block | ||||
|---|---|---|---|---|
| ||||
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: connect
namespace: kafka
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
namespace: kafka
labels:
webhook: "true"
annotations:
# use-connector-resources configures this KafkaConnect
# to use KafkaConnector resources to avoid
# needing to call the Connect REST API directly
strimzi.io/use-connector-resources: "true"
spec:
image: ktimoney/strimzi-file-connect
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
- secretName: my-cluster-clients-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: connect
certificate: user.crt
key: user.key
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1 |
We are connecting to the 9093 tls port so we include required certificates in our configuration.
The image tag references the image we built earlier : ktimoney/strimzi-file-connect
In the metadata section of KafkaConnect I have added a new label webhook: "true", this will be picked up by the MutatingWebhookConfiguration:
| Code Block | ||||
|---|---|---|---|---|
| ||||
apiVersion: admissionregistration.k8s.io/v1
kind: MutatingWebhookConfiguration
metadata:
name: kafka-webhook-config
namespace: kafka
annotations:
cert-manager.io/inject-ca-from-secret: kafka/kafka-webhook-cert
webhooks:
- name: kafka-webhook.kafka.svc.cluster.local
admissionReviewVersions:
- "v1"
sideEffects: "None"
timeoutSeconds: 30
objectSelector:
matchLabels:
webhook: "true" |
matchLabels: webhook: "true"
Create the Sink connector
| Code Block | ||||
|---|---|---|---|---|
| ||||
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-sink-connector
namespace: kafka
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: org.apache.camel.kafkaconnector.file.CamelFileSinkConnector
tasksMax: 1
config:
topics: my-topic
value.converter: org.apache.kafka.connect.storage.StringConverter
key.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
value.converter.schemas.enable: false
camel.sink.endpoint.fileName: mydata-${date:now:ddMMyy-hhmmss-SSS}.txt
camel.sink.path.directoryName: /opt/kafka/data
camel.sink.endpoint.fileExist: Append
camel.sink.endpoint.autoCreate: true
camel.aggregation.disable: true |
The KafkaConnector is configured to use the "org.apache.camel.kafkaconnector.file.CamelFileSinkConnector" class.
The value converter is set to "org.apache.kafka.connect.storage.StringConverter".
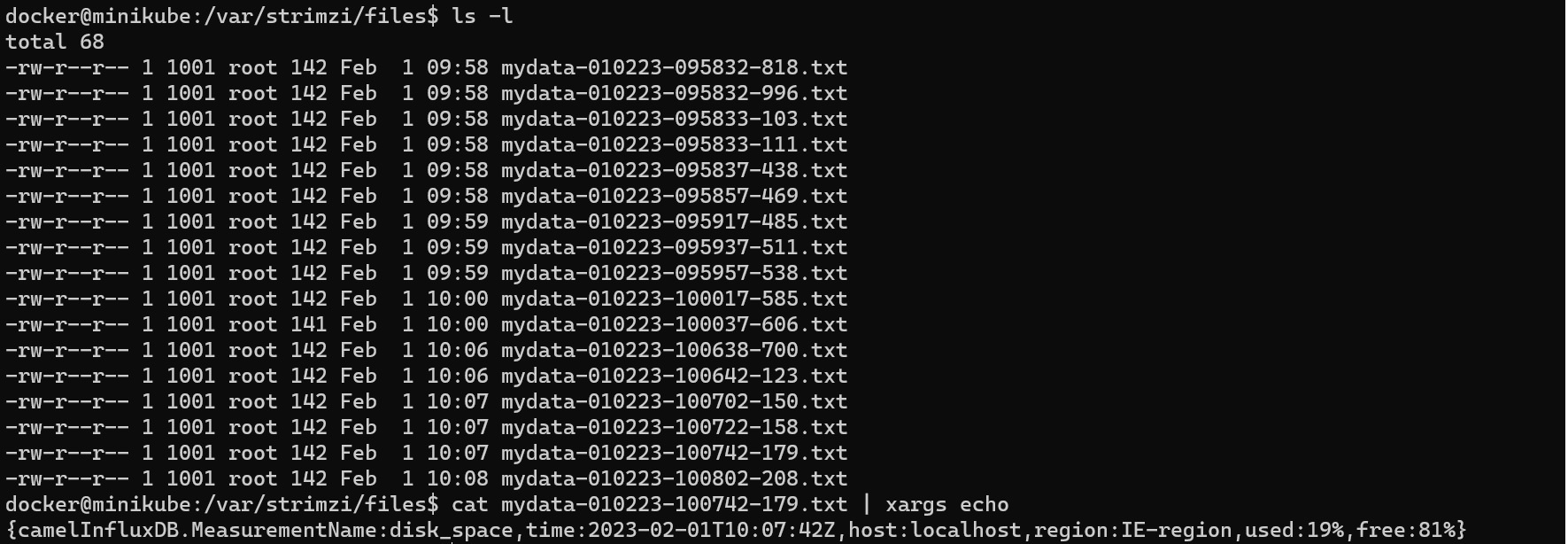
The connector filename is set using the expression: mydata-${date:now:ddMMyy-hhmmss-SSS}.txt
When the connector starts your kafka records will be copied to the persistent volume as files:
Links
Building your own Kafka Connect Building your own Kafka Connect image with a custom resource
...
How to Write a Connector for Kafka Connect – Deep Dive into Configuration Handling
Camel Kafka Connector Examples
Camel Kafka Connect Maven Repository
Camel Kafka Connector Source Code
Using secrets in Kafka Connect configuration