Introduction
Kafka Connect allows you to continuously ingest data from external systems into Kafka via connect sources and write data from Kafka to external system via connect sinks.
Various plugins are available for a variety of different data sources and data sinks.
Single Message Transformations (SMTs) are applied to messages as they flow through Connect.
Connect Demo
Postgres JDBC Sink Connector (Confluent)
Prepare the connector image
Download the JDBC sink connector from JDBC Connector (Source and Sink)
Create a docker file for this connector
FROM quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 USER root:root RUN mkdir -p /opt/kafka/plugins/jdbc COPY ./confluentinc-kafka-connect-jdbc-10.6.0.zip /opt/kafka/plugins/j dbc/ RUN unzip /opt/kafka/plugins/jdbc/confluentinc-kafka-connect-jdbc-10.6.0.zip -d /opt/kafka/plugins/jdbc RUN rm /opt/kafka/plugins/jdbc/confluentinc-kafka-connect-jdbc-10.6.0.zip USER 1001
Build the image and copy it to your docker repository
docker build -f Dockerfile . t ktimoney/strimzi connector
Prepare the postges database
Setup a new username/password and schema for Kafka connect to write to
SELECT 'CREATE DATABASE kafka'
WHERE NOT EXISTS (SELECT FROM pg_database WHERE datname = 'kafka')\gexec
DO $$
BEGIN
IF NOT EXISTS (SELECT FROM pg_user WHERE usename = 'kafka') THEN
CREATE USER kafka WITH PASSWORD 'kafka';
GRANT ALL PRIVILEGES ON DATABASE kafka TO kafka;
END IF;
END
$$;
Prepare the message producer
In this example we are going to deserialize the kafka key and value to json, for this to work we need to include the json schema with the message.
They will take the following format:
{
"schema": {
"type": "struct",
"optional": false,
"version": 1,
"fields": [
{
"field": "id",
"type": "string",
"optional": true
}
]
},
"payload": {
"id": 1
}
}
The above structure can be represented in golang using the following structs:
type SchemaPayload[T any] struct {
Schema Schema `json:"schema"`
Payload T `json:"payload"`
}
type Schema struct {
Type string `json:"type"`
Optional bool `json:"optional"`
Version int `json:"version"`
Fields []Fields `json:"fields"`
}
type Fields struct {
Field string `json:"field"`
Type string `json:"type"`
Optional bool `json:"optional"`
}
type KeyPayload struct {
Id string `json:"id"`
}
type ValuePayload struct {
Text string `json:"text"`
}
We can use the same SchemaPayload struct for both keys and values, we only need to provide the Payload struct type we initialize it with.
Create the KafkaConnect object
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: connect
namespace: kafka
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
namespace: kafka
annotations:
# use-connector-resources configures this KafkaConnect
# to use KafkaConnector resources to avoid
# needing to call the Connect REST API directly
strimzi.io/use-connector-resources: "true"
spec:
image: ktimoney/strimzi-connect
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
- secretName: my-cluster-clients-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: connect
certificate: user.crt
key: user.key
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
# -1 means it will use the default replication factor configured in the broker
config.storage.replication.factor: -1
offset.storage.replication.factor: -1
status.storage.replication.factor: -1
We are connecting to the 9093 tls port so we include required certificates in our configuration.
The image tag references the image we built earlier : ktimoney/strimzi-connect
Create the Sink connector
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-sink-connector
namespace: kafka
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: io.confluent.connect.jdbc.JdbcSinkConnector
tasksMax: 2
config:
topics: my-topic
connection.url: jdbc:postgresql://postgres.default:5432/kafka
connection.user: kafka
connection.password: kafka
key.converter: org.apache.kafka.connect.json.JsonConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: true
value.converter.schemas.enable: true
pk.mode: record_key
pk.fields: id
auto.create: true
delete.enabled: true
The KafkaConnector is configured to use the "io.confluent.connect.jdbc.JdbcSinkConnector" class.
The converters are set to "org.apache.kafka.connect.json.JsonConverter"
The pk.mode is set to "record_key" and pk.fields is set to "id", this means it will use the id field from the key as the primary key.
The database connection details are also included.
Influxdb Sink Connector (Apache Camel)
Prepare the connector image
Download the Influxdb connector: wget https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-influxdb-kafka-connector/0.8.0/camel-influxdb-kafka-connector-0.8.0-package.tar.gz
Create a docker file for this connector
FROM quay.io/strimzi/kafka:0.22.1-kafka-2.7.0 USER root:root RUN mkdir -p /opt/kafka/plugins/camel COPY ./camel-influxdb-kafka-connector-0.8.0-package.tar.gz /opt/kafka/plugins/camel/ RUN tar -xvzf /opt/kafka/plugins/camel/camel-influxdb-kafka-connector-0.8.0-package.tar.gz --directory /opt/kafka/plugins/camel RUN rm /opt/kafka/plugins/camel/camel-influxdb-kafka-connector-0.8.0-package.tar.gz USER 1001
Build the image and copy it to your docker repository
docker build -f Dockerfile . t ktimoney/strimzi_influxdb_connector
Prepare the message producer
In this example we are going to deserialize the value to json, we can do this without using a schema.
They will take the following format:
{
"camelInfluxDB.MeasurementName":"disk_space"
"time":"2023-01-23T13:03:31Z"
"host":"localhost"
"region":"IE-region"
"used":"19%"
"free":"81%"
}
The important thing to note here is that one of the "keys" has to be "camelInfluxDB.MeasurementName", this is required by the camel transformer when converting into an influxdb point object.
The above structure can be represented in golang using the following struct:
type InfluxPayload struct {
Measurement string `json:"camelInfluxDB.MeasurementName"`
Time string `json:"time"`
Host string `json:"host"`
Region string `json:"region"`
Used string `json:"used"`
Free string `json:"free"`
}
Create the KafkaConnect object
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: connect
namespace: kafka
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
namespace: kafka
annotations:
# use-connector-resources configures this KafkaConnect
# to use KafkaConnector resources to avoid
# needing to call the Connect REST API directly
strimzi.io/use-connector-resources: "true"
spec:
image: ktimoney/strimzi-influxdb-connect
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
- secretName: my-cluster-clients-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: connect
certificate: user.crt
key: user.key
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
We are connecting to the 9093 tls port so we include required certificates in our configuration.
The image tag references the image we built earlier : ktimoney/strimzi-influx-connect
Create the Sink connector
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-sink-connector
namespace: kafka
labels:
strimzi.io/cluster: my-connect-cluster
spec: class: org.apache.camel.kafkaconnector.influxdb.CamelInfluxdbSinkConnector
tasksMax: 1
config:
topics: my-topic
errors.deadletterqueue.topic.name: my-topic-dl
errors.deadletterqueue.topic.replication.factor: 1
key.converter: org.apache.kafka.connect.storage.StringConverter
value.converter: org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable: false
value.converter.schemas.enable: false
key.ignore: true
auto.create: true
camel.beans.influx: "#class:org.influxdb.InfluxDBFactory#connect('http://influxdb.default:8086', 'influxdb', 'influxdb')"
camel.sink.path.connectionBean: influx
camel.sink.endpoint.databaseName: ts_host_metrics
camel.sink.endpoint.operation: insert
camel.sink.endpoint.retentionPolicy: autogen
The KafkaConnector is configured to use the "org.apache.camel.kafkaconnector.influxdb.CamelInfluxdbSinkConnector" class.
The value converter are set to "org.apache.kafka.connect.json.JsonConverter".
The camel connector comes with a in built TypeConverter called CamelInfluxDbConverters which will read the json produced as a Map<String, Object> map) and return an Influxdb Point object.
The database connection details are specified in camel.beans.influx.
This sets up a connection bean to be used by camel.sink.path.connectionBean.
Note: It is important to wrap the camel.beans.influx parameter in quotes otherwise it will be treated as a comment.
The yaml for the influxdb pod is available here: influxdb.yaml
When the connector is running it will produce records to influxdb like the following:
{'pretty': 'true', 'db': 'ts_host_metrics', 'q': 'SELECT "region", "host", "free", "used" FROM "disk_space" WHERE "host"=\'localhost\''}
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "disk_space",
"columns": [
"time",
"region",
"host",
"free",
"used"
],
"values": [
[
"2023-01-23T13:03:32.1246436Z",
"IE-region",
"localhost",
"81%",
"19%"
]
]
}
]
}
]
}
Minio Sink Connector (Apache Camel)
Prepare the connector image
Download the minio sink connector: wget https://repo.maven.apache.org/maven2/org/apache/camel/kafkaconnector/camel-minio-sink-kafka-connector/3.19.0/camel-minio-sink-kafka-connector-3.19.0-package.tar.gz
Create a docker file for this connector
FROM quay.io/strimzi/kafka:0.32.0-kafka-3.3.1 USER root:root RUN mkdir -p /opt/kafka/plugins/camel COPY ./camel-minio-sink-kafka-connector-3.19.0-package.tar.gz /opt/kafka/plugins/camel/ RUN tar -xvzf /opt/kafka/plugins/camel/camel-minio-sink-kafka-connector-3.19.0-package.tar.gz --directory /opt/kafka/plugins/camel RUN rm /opt/kafka/plugins/camel/camel-minio-sink-kafka-connector-3.19.0-package.tar.gz USER 1001
Build the image and copy it to your docker repository
docker build -f Dockerfile . t ktimoney/strimzi_minio_connector
Prepare the message producer
In this example we are going to deserialize the value to a string. (Same producer as the influxdb example)
They will take the following format:
{
"camelInfluxDB.MeasurementName":"disk_space"
"time":"2023-01-23T13:03:31Z"
"host":"localhost"
"region":"IE-region"
"used":"19%"
"free":"81%"
}
Create the KafkaConnect object
apiVersion: kafka.strimzi.io/v1beta1
kind: KafkaUser
metadata:
name: connect
namespace: kafka
labels:
strimzi.io/cluster: my-cluster
spec:
authentication:
type: tls
---
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnect
metadata:
name: my-connect-cluster
namespace: kafka
annotations:
# use-connector-resources configures this KafkaConnect
# to use KafkaConnector resources to avoid
# needing to call the Connect REST API directly
strimzi.io/use-connector-resources: "true"
spec:
image: ktimoney/strimzi-minio-connect
replicas: 1
bootstrapServers: my-cluster-kafka-bootstrap:9093
tls:
trustedCertificates:
- secretName: my-cluster-cluster-ca-cert
certificate: ca.crt
- secretName: my-cluster-clients-ca-cert
certificate: ca.crt
authentication:
type: tls
certificateAndKey:
secretName: connect
certificate: user.crt
key: user.key
config:
group.id: connect-cluster
offset.storage.topic: connect-cluster-offsets
config.storage.topic: connect-cluster-configs
status.storage.topic: connect-cluster-status
offset.storage.topic: my-connect-cluster-offsets
config.storage.topic: my-connect-cluster-configs
status.storage.topic: my-connect-cluster-status
config.storage.replication.factor: 1
offset.storage.replication.factor: 1
status.storage.replication.factor: 1
We are connecting to the 9093 tls port so we include required certificates in our configuration.
The image tag references the image we built earlier : ktimoney/strimzi-minio-connect
Create the Sink connector
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: my-sink-connector
namespace: kafka
labels:
strimzi.io/cluster: my-connect-cluster
spec:
class: org.apache.camel.kafkaconnector.miniosink.CamelMiniosinkSinkConnector
tasksMax: 1
config:
topics: my-topic
key.converter: org.apache.kafka.connect.storage.StringConverter
value.converter: org.apache.kafka.connect.storage.StringConverter
key.converter.schemas.enable: false
value.converter.schemas.enable: false
key.ignore: true
camel.kamelet.minio-sink.bucketName: camel
camel.kamelet.minio-sink.accessKey: ybK7RleFUkdDeYBf
camel.kamelet.minio-sink.secretKey: X0Y4zK84bwdefRTljrnPzOb1l0A6OQj2
camel.kamelet.minio-sink.endpoint: http://minio.default:9000
camel.kamelet.minio-sink.autoCreateBucket: true
The KafkaConnector is configured to use the "org.apache.camel.kafkaconnector.miniosink.CamelMiniosinkSinkConnector class.
The value converter are set to "org.apache.kafka.connect.storage.StringConverter".
We will need to create our own TypeConverter and include it with the camel connector if we want to deserialize using org.apache.kafka.connect.json.JsonConverter.
The minio connection details are specified in camel.kamelet.minio-sink parameters.
The yaml for the minio pod is available here: minio.yaml
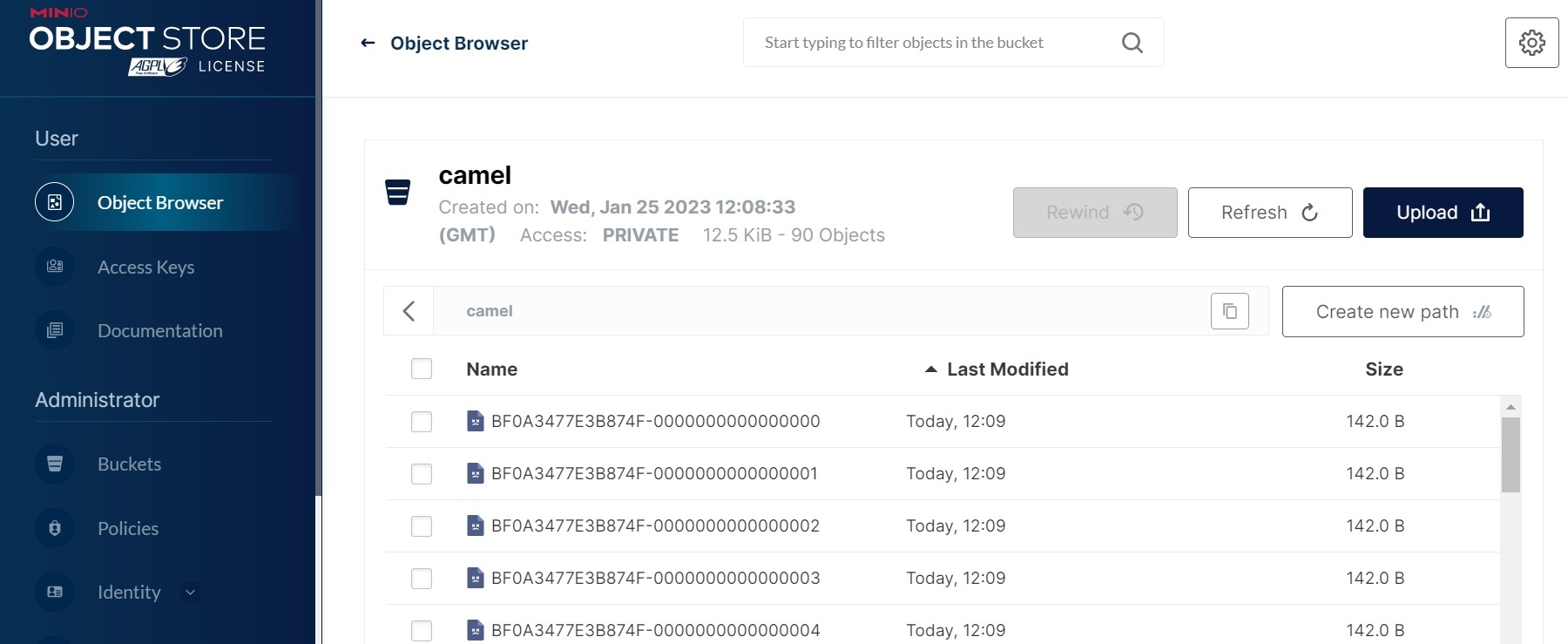
When the connector is running it copies the kafka records into minio as files:
Links
Building your own Kafka Connect image with a custom resource
Kafka Connect Deep Dive – Converters and Serialization Explained
How to Write a Connector for Kafka Connect – Deep Dive into Configuration Handling
Camel Kafka Connector Examples