Costa Rica face-to-face (and remote)
Time zone: UTC-06:00
Oct14 -10:15 to 11:45: Session with WG2
Lead: Dhruv Gupta
IM for A1:
Kevin Scaggs
https://gerrit.o-ran-sc.org/r/admin/repos/scp/oam/modeling
A broader scope of the IM work
The O-RAN common information model should align the different WGs in terms of modeling, terminology, definitions, … avoiding different modeling and solutions for the same functionalities.
- A serial number is a serial number is a serial number
- SW management is SW management is SW management
In addition, the IM work aligns the work with 3GPP (not relevant for A1 as A1 is a pure O-RAN exercise) and addresses gaps from the operator's point of view.
What are the expected deliverables, and expectations from WG2?
WG1 IM would need input from WG2 for the object and attributes to be modeled and related use case descriptions and workflows.
PM data according to WG1 Architecture and Interface specification should be streamed via VES to SMO. Are there gaps in the VES format for PM data?
Oct15 -16:30 to 18:15: Session with WG1
Lead: Kevin Scaggs(Information modeling part, Papyrus); Martin Skorupski(yang)
Alignment across UML Information models
O-RAN Working group 1 (WG1) is going to provide information models for the different interfaces, which O-RAN feels responsible for. Such interfaces (APIs) are:
A1, E2, O1, O1* and OpenFronthaul.
One main target is the alignment with 3GPP models. Therefore the main object classes are ManagedElement and ManagedFunction. Such object classes are common for all O-RAN interfaces and will be part of the O-RAN common information model.
However, the common information model must not include the A1, E2, O1, O1* and OpenFronthaul specific object classes. Those are defined, reviewed and agreed in the related working groups domains. WG1 IM takes care to create the corresponding information model.
The result is a common information model and interface-specific submodules.
Dependencies and model hierarchy
O-RAN Common Information Model
- A1 Information Model
- E2 Information Model
- O1 Information Model
- O1* Information Model
- OpenFronthaul Information Model
Alignment between UML information models and YANG/SWAGGER/ASN1 data models
UML visualize models and is needed to explain, share and discuss models. However, related data models will be implemented. The O-RAN Alliance Architecture and Operation and Maintenance interface specification selected NetConf/Yang as API Protocol and data schema.
As a consequence, the UML must be transformed mapped to YANG models. Ideally, there would be tooling, which simply converty UML to YANG (or others schemas). The challenge is that UML is usually much more powerful, than the schemas. For an automatic translation, mapping rules and UML guidelines are defined to "restrict" the complexity and various options of UML.
The IISOMI project (Informal Inter-SDO Open Model Initiative) has created such guidelines, rules and processes.
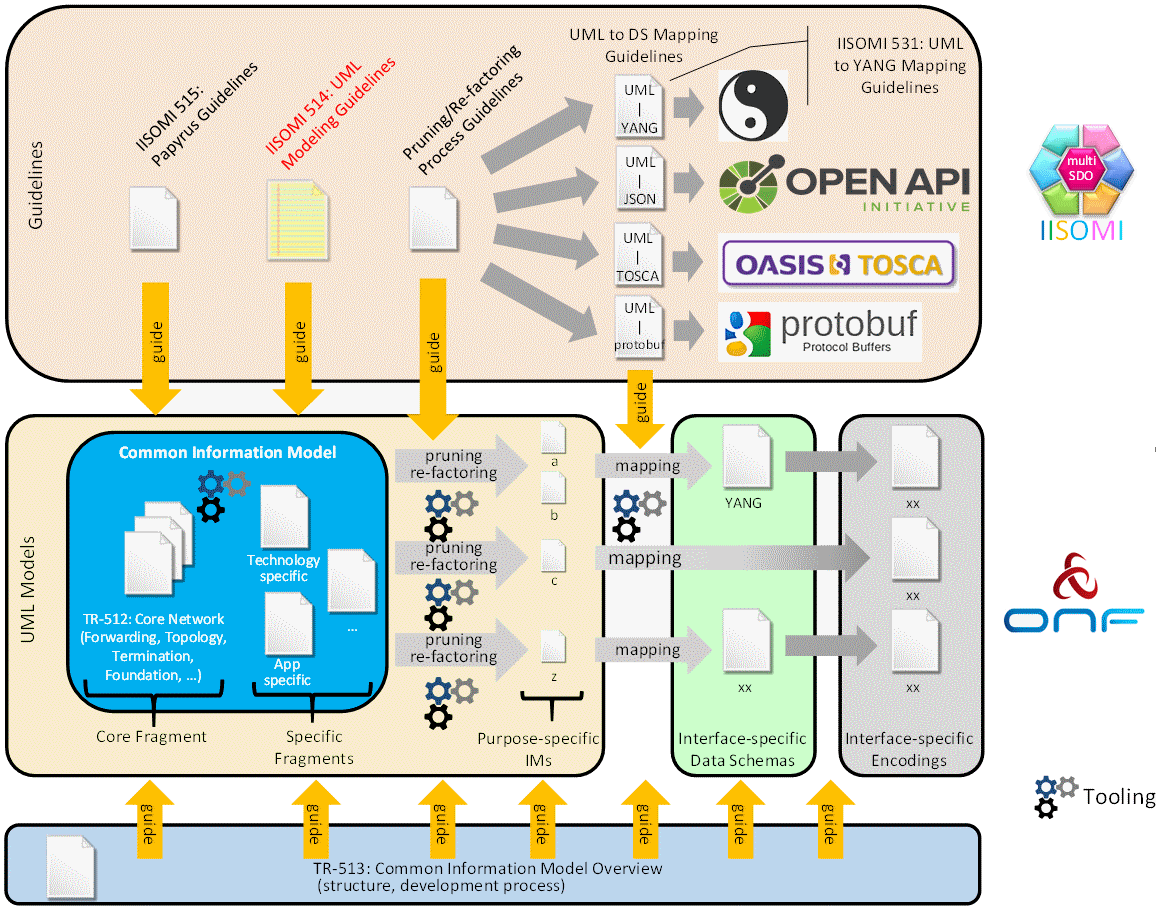
Source: IISOMI
- Wednesday, October 16, 2019
- Alignment across UML Information models and YANG data models
- [16:30 – 17:00] SA: Information Modeling – 30 minutes
[sko] between the UMLs
-> Common and submodules
I can take:
Alignment between UML IM and YANG Data models
-> IISOMI has a process an tooling, but it would require that UML modules follow the exact guidelines, which is problematic.
If automation does not work, then manual works, however also a semi-automated process works, where all the object classes, attribute names and description are converted to yang.
- Reconcile O-RAN IM with other open source project models
[sko] May statement on this is:
- VES -> 100% reused missing functions from O-RAN point of view are contributed to ONAP VES
- It is good that Kevin is active in O-RAN and ONAP modeling groups;
- We are in a process to add missing functions of 3GPP into the O-RAN IM – but this work just started:
-- identifications, names,
-- lifecycle management
-- required vs actual equipment
…
[kevin] can certainly touch on the Ves model, not sure what all is intended here. Maybe we can cover this jointly?
- Inputs for O-RAN Information Model Specification v1.0
[sko] I think this is your right? I’m not sure what is meant in details?!?!
[kevin] Not sure what all is intended here. Certainly we can touch on the A1P spec, the O1 spec, possible material on O1 / O1*, 3GPP foundational material??? Maybe this is another joint item.
- [17:00 – 18:00] SA: Information Modeling tutorial – 60 minutes + ad hoc /spare
- YANG modeling and Papyrus tool
Can you take the papyrus tool?
[sko] I can take yang modeling:
Why YANG?
What is YANG?
How is the process from UML to yang.
[kevin] I am prepared for the tutorial. Have a light deck that will define an information model, some model sample diagrams, some IISOMI guidelines, and then an outline of things that will be covered in the tutorial (getting around, creating a diagram, creating a class, creating an attribute, creating a comment, applying filters, applying an IISOMI stereotype, modifying an item’s appearance, creating a datatype, creating an association, finding stuff…). This will have to be pretty fast and simple to cover the outline.
Should be recorded and upload to wiki for study
- [18:00 – 18:15] Coffee Break